
A Curva ROC (Receiver Operating Characteristic) e a AUC (Area Under the Curve) são ferramentas poderosas para medir e comparar o desempenho de modelos de classificação binários, em machine learning.
A Curva ROC é um gráfico simples, mas robusto, que permite estudar a variação da sensibilidade e especificidade, para diferentes pontos de corte na probabilidade estimada (thresholds). A AUC é uma medida de área que facilita a comparação entre Curvas ROC. Entenda os detalhes neste artigo.
O que é a Curva ROC (Receiver Operating Characteristic)
Uma curva ROC é capaz de demonstrar o desempenho de um modelo de machine learning, que seja um classificador binário, por meio da relação da Taxa de Verdadeiro Positivo (Sensibilidade) e da Taxa de Falso Positivo ( ), variando o threshold (ponto de corte na probabilidade estimada).
), variando o threshold (ponto de corte na probabilidade estimada).
Veja que um modelo de classificação binária geralmente é capaz de fornecer uma probabilidade da variável target ser  , e não uma resposta fixa de 0 ou 1. Sendo assim, é possível definirmos diversos thresholds, que:
, e não uma resposta fixa de 0 ou 1. Sendo assim, é possível definirmos diversos thresholds, que:
- irão definir as labels da predição do algoritmo entre 0 e 1 (quanto mais próximo de 1 o threshold, mais valores serão preditos como 0; quanto mais próximo de 0 o threshold, mais valores serão preditos como 1);
- irão permitir calcular diversas taxas de (i) verdadeiro positivo e de (ii) falso positivo para cada nível de threshold, que serão justamente as duas colunas de dados necessárias para criar o gráfico da Curva ROC.
Dessa forma, a Curva ROC permite encontrar o threshold em que existe otmização da sensibilidade em função da especificidade. O ponto onde ocorre esta otimização é aquele que se encontra mais próximo do canto superior esquerdo do gráfico da curva ROC. Ou seja:
o objetivo de analisar o poder preditivo de um modelo é garantir que ele irá detectar o máximo possível de verdadeiros positivos, enquanto minimiza os falsos positivos.
Como construir a Curva ROC?
Para construir a Curva ROC é preciso:
- elencar os dados em ordem decrescente da probabilidade estimada pelo modelo;
- calcular a taxa de verdadeiro positivo (será o eixo y da curva) e a taxa de falso positivo (que será o eixo x da curva) para cada linha (sempre considerando de forma cumulativa). Neste passo considera-se a probabilidade estimada da linha como sendo o threshold.
- criar o gráfico com a taxa de verdadeiro positivo no eixo Y e a taxa de falso positivo no eixo X.
Neste link preparei uma planilha com um exemplo para você entender melhor os passos citados.
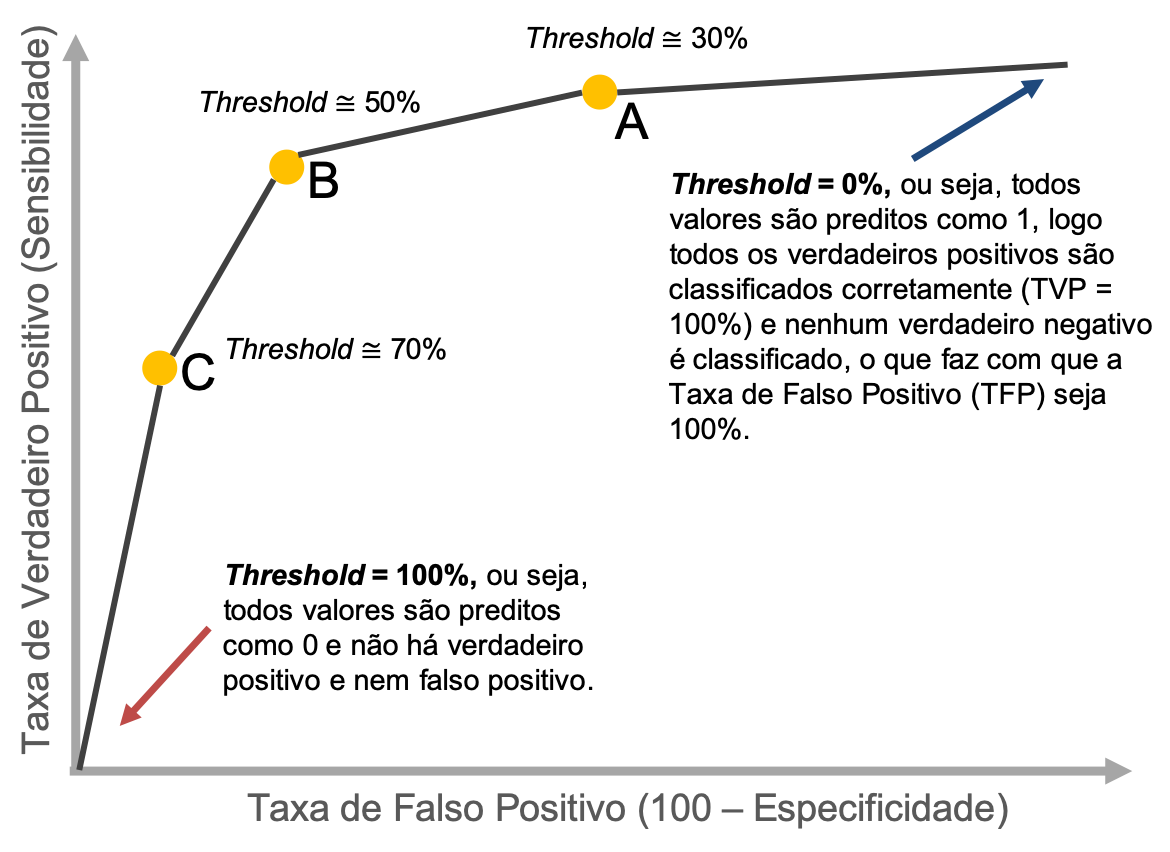
Veja a figura a seguir, que demonstra como a Curva ROC se comporta ao longo de diferentes pontos de corte (thresholds) na probabilidade.
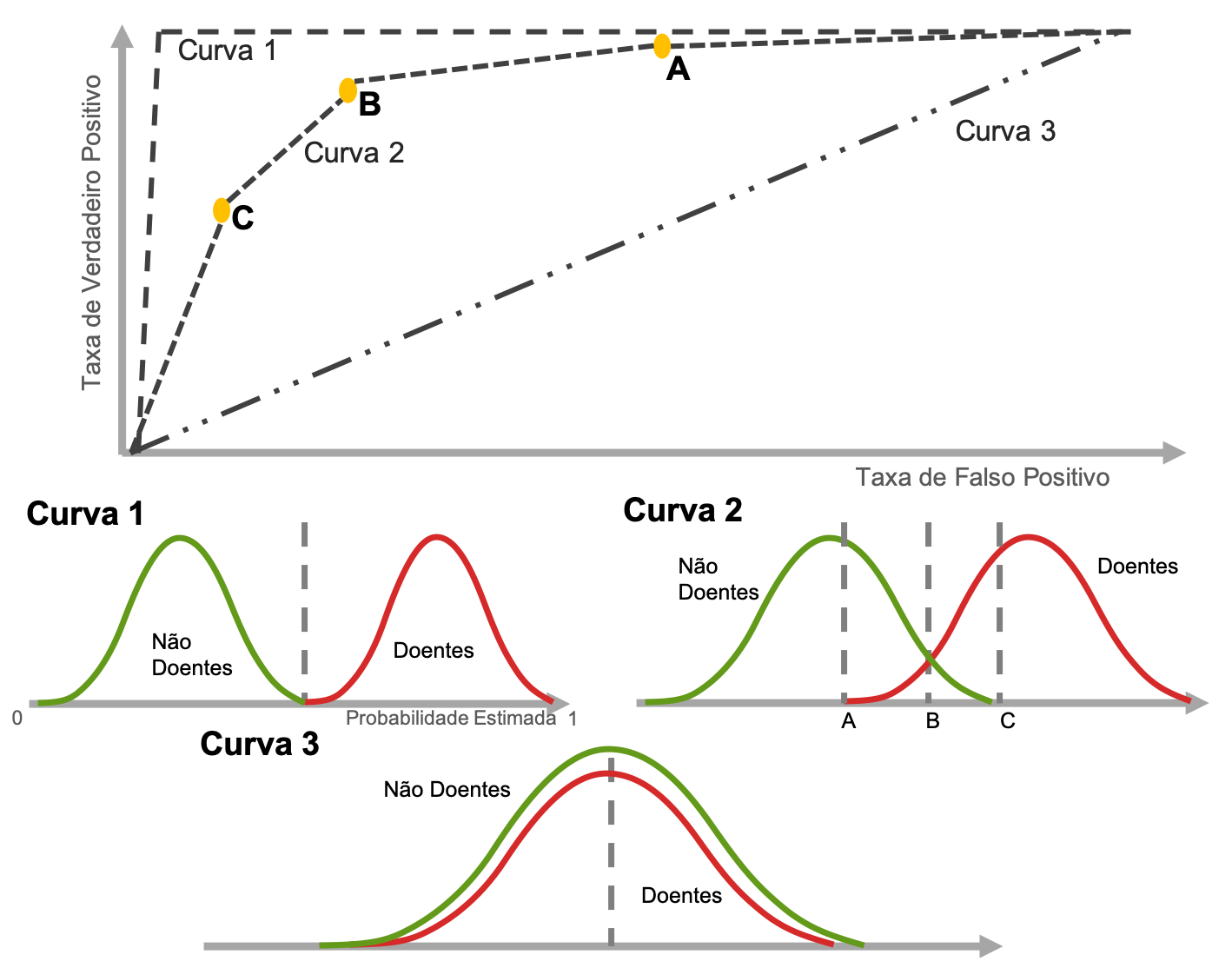
Exemplos de Curva ROC para casos hipotéticos
As descrições e as imagens a seguir demonstram alguns exemplos de como ficam as curvas ROC para casos hipotéticos:
-
Curva 1 – Modelo perfeito: a medida que o threshold vai diminuindo o modelo nunca comete um falso positivo e a taxa de verdadeiro positivo está sempre em 100%.
-
Curva 2 – Modelo usual: comete alguns falsos positivos e falsos negativos.
-
Curva 3 – Modelo que não agrega: um modelo que não agrega nada a mais em relação a chutes aleatórios.
Há ainda os modelos (não demonstrados graficamente aqui) que são piores que o caso aleatório. Nestes casos a curva fica abaixo da curva 3 apresentada.
Considerações importantes sobre a construção da Curva ROC
Alguns pontos:
- Quando o threshold é 1, então todos os valores serão preditos como 0, o que faz com que não haja nenhuma verdadeiro positivo e nenhum falso positivo. O que torna a TVP = 0 e a TFP = 0.
- A medida em que o threshold é reduzido, começam a surgir os casos de verdadeiro positivo e falso positivo, aumentando as TVP e TFP.
- A ideia é que os verdadeiros positivos (VP) sejam clasificados em um número maior possível a medida que o threshold é reduzido, antes que os falsos positivos comecem a aumentar muito.
- O threshold ótimo pode ser escolhido pelo ponto onde a variação do crescimento do crescimento da curva ROC começa a cair. Em outras palavras, no ponto em que temos a maior possível TVP para a menor possível TFP.
- O modelo utópico perfeito classifica todos os verdadeiros positivos corretamente sem nenhum falso positivo, tendo TVP = 100% e TFP = 0%.
- Se o threshold for 0, então todos valores serão preditos como 1, o que faz com que todos os verdadeiros positivos sejam classificados corretamente (TVP = 100%) e nenhum verdadeiro negativo seja classificado. Como não há verdadeiro negativo, então a Taxa de Falso Positivo (TFP) é 100% também.
O que é AUC (Area Under the Curve)?
Em alguns casos práticos a Curva ROC não fica tão “suave” como nos exemplos didáticos. Isto ocorre por algumas razões, como:
- Não há muitos dados de teste, sobre os quais o modelo é aplicado e avaliado;
- Características específicas do modelo aplicado que fazem com que diversas linhas de dados similares tenha a mesma probabilidade estimada.
Nestes casos pode ficar difícil comparar visualmente qual modelo possui melhor Curva ROC, pois as curvas podem se cruzar em diferentes pontos.
É aí que entra a Area Under the Curve (AUC), a área do gráfico que fica sob a curva.
O valor do AUC varia de 0,0 até 1,0, ou de 0% a 100%. Quanto maior o AUC, melhor.
Um modelo cujas previsões estão 100% erradas tem uma AUC de 0, enquanto um modelo cujas previsões são 100% corretas tem uma AUC de 1.
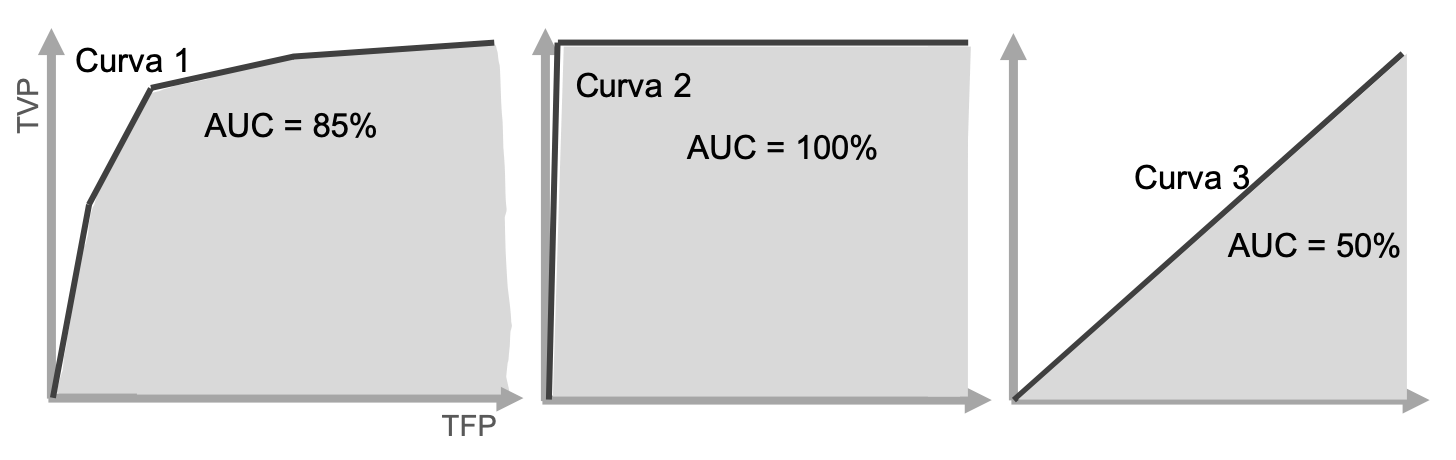
Exemplos de Curva ROC e AUC na linguagem R
Vamos construir dois modelos de machine learning na linguagem R para depois construirmos a Curva ROC de cada um deles.
Para estas análises de exemplo utilizaremos um conjunto de dados fictícios (explicado a seguir). Iremos também precisar dos seguintes pacotes:
# Básicos / genéricos
library(knitr) # Criar HTML
library(tidyverse) # Transformação de dados
# Específicos deste post
library(neuralnet) # Redes Neurais
library(pROC) # Curva ROC
Leitura dos dados e metodologia
Analisaremos um conjunto de dados dos passageiros do navio Titanic, que naufragou em 1912. Então aplicaremosos modelos (regressão logística e rede neural) para calcular o probabilidade de um passageiro, ao embarcar no navio, vir a sobreviver à tragédia ( , variável dependente).
, variável dependente).
O dicionário dos dados, que mostra o significado de cada variável, é o seguinte:
survived: sobreviveu ; não sobreviveu (, variável dependente);
; não sobreviveu (, variável dependente); pclass: classe (1, 2 e 3, indicando primeira, segunda e terceira classe);sex: masculino (male) e feminino (female);age: idade do passageiro;sibsp: número de irmãos e cônjuge (siblings and spouse) a bordo;parch: número de pais e filhos (parents and children) a bordo;fare: tarifa paga pelo passageiro.
 ; não sobreviveu
; não sobreviveu  (
(Veja como é o head dos dados (5 primeiras observações):
# Download e seleção das variáveis desejadas
df_titanic <-
readr::read_csv("https://gitlab.com/dados/open/raw/master/titanic.csv") %>%
dplyr::select(passengerid, survived, pclass, sex, age, sibsp, parch, fare)
# Head dos dados
head(df_titanic, 5) %>% knitr::kable()
| passengerid | survived | pclass | sex | age | sibsp | parch | fare |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | male | 22 | 1 | 0 | 7.2500 |
| 2 | 1 | 1 | female | 38 | 1 | 0 | 71.2833 |
| 3 | 1 | 3 | female | 26 | 0 | 0 | 7.9250 |
| 4 | 1 | 1 | female | 35 | 1 | 0 | 53.1000 |
| 5 | 0 | 3 | male | 35 | 0 | 0 | 8.0500 |
A seguir são feitos alguns tratamentos nos dados:
- Transformar variáveis do tipo
characterparafactor. - Criar variáveis binárias (dummies) dos fatores. Este é um passo necessário para o
inputdos dados nas funções aqui utilizadas.
# Tratamentos nos dados
df_titanic <-
df_titanic %>%
dplyr::mutate_if(is.character, as.factor) %>% # Transformando do tipo character para factor
dplyr::mutate(survived = as.factor(survived), # Transformando do tipo numéricas para factor
pclass = as.factor(pclass)
) %>%
bind_cols(as_tibble(model.matrix(~ sex + pclass - 1, data = .))) %>% # Criando variáveis binárias
na.omit() # Excluindo NA's
Definindo a fórmula que será utilizada nos modelos, para garantir que seja a mesma:
fml <- formula(survived ~ pclass2 + pclass3 + sexmale + age + sibsp + parch + fare)
em que survived é a variável dependente () e as demais são as variáveis independentes ( ).
).
Dividindo o dataset em treino e teste
Existem diversas formas de fazer esta divisão pela linguagem R. Não há jeito certo ou errado. O importante é chegar ao objetivo de dividir o dataset.
# O seed é um número que garante que a geração "aleatória" do computador será sempre a mesma.
# Assim garanto que meu exemplo é reproduzível.
set.seed(123)
# Criar o subset de treino
train <- df_titanic %>% dplyr::sample_frac(.70)
# Criar o subset de teste com antijoin (pega tudo que não pertence)
test <- dplyr::anti_join(df_titanic, train, by = 'passengerid')
Modelo 1. Regressão Logística
Vamos utilizar a função glm(), nativa do R. Apenas certifique-se de configurar o parâmetro family para family = binomial(link = 'logit'). No termo da equação, a variável target é precedida de ~. Esta, inclusive, é uma terminologia padrão para a maior parte das funções de modelos supervisionados de machine learning no R.
Importante: o modelo será aplicado no dataset de treino, e não no dataset completo.
# Rodando o modelo
fit_reg_log <-
glm(
fml,
family = binomial(link = 'logit'),
data = train
)
# Fazendo as predições
pred_reg_log <- predict(fit_reg_log, newdata = test, type = "response")
# Organizando a tabela de dados para calcular as métricas da curva ROC
pred_roc_reg_log <-
dplyr::tibble(
pred_reg_log,
"survived" = as.factor(as.numeric(test$survived)-1)
) %>% arrange(desc(pred_reg_log))
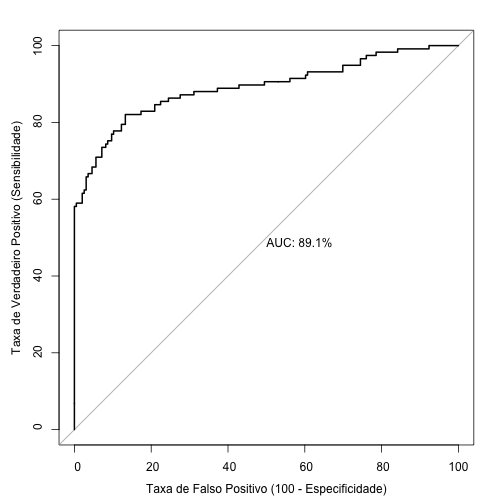
Curva ROC para regressão logística
Veja a Curva ROC do modelo de regressão logística estimado.
# Criando objeto com as métricas para curva ROC
roc_reg_log <- pROC::roc(pred_roc_reg_log$survived , pred_roc_reg_log$pred_reg_log, percent = TRUE)
# Se desejar, é possível (e bem simples) utilizar o próprio pacote pROC para plotar a curva ROC.
par(pty = "s")
plot.roc(
roc_reg_log,
print.auc = TRUE,
legacy.axes = TRUE,
xlab = "Taxa de Falso Positivo (100 - Especificidade)",
ylab = "Taxa de Verdadeiro Positivo (Sensibilidade)"
)
Modelo 2. Rede neural
Vamos agora estimar uma Rede Neural com duas camadas (hidden layers) de três neurônios cada.
Veja mais sobre Redes Neurais Artificiais aqui.
set.seed(123)
# Estimando o modelo
fit_net <- neuralnet(
fml ,
train,
hidden = c(3,3),
threshold = .2, # aumentar o threshold reduz o tempo para rodar, mas compromete a acurácia do modelo.
err.fct = "sse",
linear.output = FALSE
)
# Fazendo as predições
pred_net <- predict(fit_net,
newdata = test)[, 2] # segunda coluna para pegar apenas survived = 1
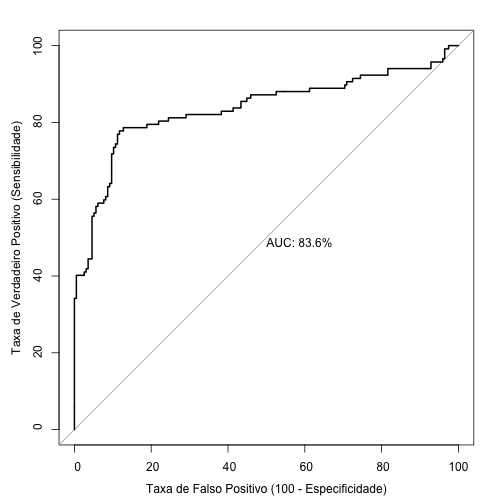
Curva ROC para Redes Neurais Artificiais
Veja a curva ROC para o modelo de Redes Neurais estimado.
pred_roc_net <-
tibble(pred_net, "survived" = as.factor(as.numeric(test$survived)-1)) %>%
dplyr::arrange(desc(pred_net))
roc_net <- roc(pred_roc_net$survived , pred_roc_net$pred_net, percent = TRUE)
par(pty = "s")
plot.roc(
roc_net,
print.auc = TRUE,
legacy.axes = TRUE,
xlab = "Taxa de Falso Positivo (100 - Especificidade)",
ylab = "Taxa de Verdadeiro Positivo (Sensibilidade)"
)
Comparando a curva ROC dos dois modelos
Olhando Curva ROC individual de cada modelo pode ser difícil conseguir comparar os modelos.
Sendo assim, vale a pena criar um gráfico mesclando as Curvas ROC e apresentando a AUC dos distintos modelos executados, conforme segue:
par(pty = "s")
plot(roc_reg_log, print.auc = TRUE, col = "blue", main = "ROC", legacy.axes = TRUE,
xlab = "% de Falso Positivo (100 - Especificidade)",
ylab = "% de Verdadeiro Positivo (Sensibilidade)")
plot(roc_net, print.auc = TRUE, col = "green", print.auc.y = 40, add = TRUE, legacy.axes = TRUE)
legend("bottomright", legend=c("Regressão Logística", "Rede Neural"),
col= c("blue", "green"), lwd=2)
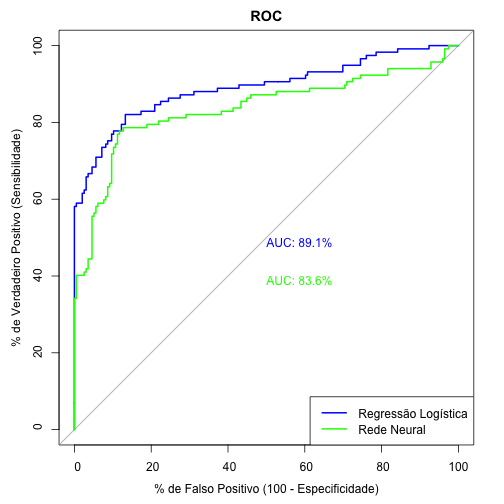
Apesar de percebermos diferenças no valor de AUC e também diferenças visuais nas construções das Curvas ROC, ainda fica a pergunta:
Dados dois modelos e as duas curvas ROC, será que a AUC dos dois modelos são estatisticamente diferentes?
Para responder esta pergunta pode-se utilizar o Teste de DeLong para duas curvas ROC. Veja o teste a seguir:
# Rodando o teste DeLong, se p-valor < 0.10, então há diferença, caso contrário não há.
roc.test(roc_reg_log, roc_net, method = "delong")
## ## DeLong's test for two ROC curves ## ## data: roc_reg_log and roc_net ## D = 1.5811, df = 591.7, p-value = 0.1144 ## alternative hypothesis: true difference in AUC is not equal to 0 ## sample estimates: ## AUC of roc1 AUC of roc2 ## 89.10692 83.63422
O p-valor do Teste de DeLong mostra se há ou não diferença estatística entre as duas Curvas ROC.
Neste caso de exemplo o resultado foi que não houve diferença estatística nas Curvas ROC para os dois modelos testados. Sendo assim, tanto faz (neste caso) escolhermos entre o modelo de regressão logística ou o de redes neurais aritificiais.
Claro que aqui foram apresentados exemplos bastante simples. Em casos práticos há uma infinidade de parametrizações possíveis de serem feitas em cada família de modelos, que podem melhor os resultados nas comparações realizadas.
Considerações sobre a Curva ROC e AUC
Este artigo mostrou o que é a Curva ROC e a AUC, com exemplos didáticos (hipotéticos) e dois casos práticos com aplicações para modelos de regressão logística e redes neurais.
Entre os modelos treinados, nem sempre é nítida a diferença entre o melhor apenas observando a curva ROC. Sendo assim, o teste de DeLong permite ter um parâmetro objetivo para ajudar na escolha do melhor modelo. O teste possui a hipótese nula ( ) de que a AUC dos testes são iguais.
) de que a AUC dos testes são iguais.
Por fim, vale ressaltar que nem sempre o aumento do porder computacional exigido traz resultados proporcionalmente melhores!, por isso a importância de analisar a performance dos modelos com ferramentas como as que foram aqui demonstradas.
Veja mais artigos na área de Machine Learning e análise de dados:
- O que é Ciência de Dados?
- Aprendizado de Máquina Supervisionado e Não Supervisionado
- Processamento de Linguagem Natural
- Árvore de Decisão na Linguagem R
- Testes de Hipóteses Estatísticas
Excelente detalhamento e demonstração! Obrigado por compartilhar!
Obrigado David! Abs.
Não é possível comentar.